Une API OpenAI. Toutes les modalités.
Votre flotte GPU.
One OpenAI API. Every modality.
Your GPU fleet.
SPT Models orchestre l'inférence GPU sur du matériel hétérogène — DGX Spark Blackwell, RTX 4090 x86, et Apple Silicon — derrière une seule API compatible OpenAI. 9 types de modèles, planification arch-aware, éviction LRU, et auto-import IA.
SPT Models orchestrates GPU inference on heterogeneous hardware — Blackwell DGX Spark, x86 RTX 4090, and Apple Silicon — behind a single OpenAI-compatible API. 9 model types, arch-aware scheduling, LRU eviction, and AI-powered auto-import.
SPT Models · démo en 88 s · 1920×1080SPT Models · 88-second demo · 1920×1080MP4 FR ·
MP4 EN
UNE SEULE API
ONE API
Neuf types de modèles. Un seul SDK OpenAI.
Nine model types. The same OpenAI SDK.
Branchez le client OpenAI standard sur votre passerelle SPT. Chat, images, vidéo, audio, embeddings, reranking — chaque endpoint suit la convention OpenAI, avec passthrough des paramètres spécifiques au modèle.
Point the standard OpenAI client at your SPT gateway. Chat, images, video, audio, embeddings, reranking — every endpoint follows OpenAI conventions, with passthrough for model-specific parameters.
Chat / LLM
POST /v1/chat/completions
Streaming SSE, batching continu, tensor parallelism via vLLM. GGUF quantisé via llama.cpp.
SSE streaming, continuous batching, tensor parallelism via vLLM. GGUF quantized via llama.cpp.
Vision / VLM
POST /v1/chat/completions
Modèles vision-langage avec entrée image. Auto-sélection vLLM ou transformers selon l'architecture.
Vision-language models with image input. Auto-selects vLLM or transformers based on architecture.
Embeddings
POST /v1/embeddings
Vecteurs float, sentence-transformers. Loader bundled pour jina-embeddings-v5.
Float vectors, sentence-transformers. Bundled loader for jina-embeddings-v5.
Rerank
POST /v1/rerank
Cross-encoder pour BGE-rerank, Cohere rerank. Optimisé pour RAG.
Cross-encoder for BGE-rerank, Cohere rerank. RAG-optimized.
Image gen
POST /v1/images/generations
Stable Diffusion, SDXL, Flux, Z-Image. Pipeline diffusers, upgrade auto si nécessaire.
Stable Diffusion, SDXL, Flux, Z-Image. Diffusers pipeline, auto-upgraded as needed.
Video gen
POST /v1/videos/generations
CogVideoX, Wan, LTX-Video. Génération texte→vidéo et image→vidéo.
CogVideoX, Wan, LTX-Video. Text-to-video and image-to-video generation.
TTS
POST /v1/audio/speech
Bark, Parler, Qwen3-TTS, omnivoice (600+ langues). Loaders custom pour multi-composant.
Whisper via faster-whisper. Voxtral, Wav2Vec2. Auto-fallback transformers si CT2 indispo.
Whisper via faster-whisper. Voxtral, Wav2Vec2. Transformers fallback if CT2 unavailable.
Diarization
POST /v1/audio/transcriptions
Sortformer (NeMo) via loader bundled. Découpage par locuteur intégré au transcript.
Sortformer (NeMo) via bundled loader. Speaker turns inlined into the transcript.
FLOTTE HÉTÉROGÈNE
HETEROGENEOUS FLEET
Un orchestrateur. Trois architectures. Aucun compromis.
One orchestrator. Three architectures. No compromise.
Le planificateur arch-aware route chaque modèle vers le GPU avec le plus de VRAM libre, en respectant les contraintes d'architecture et de runtime. CUDA et MLX cohabitent — le client gateway ne voit jamais la différence.
The arch-aware scheduler routes each model to the GPU with the most free VRAM, respecting architecture and runtime constraints. CUDA and MLX coexist — the gateway client never sees the difference.
aarch64 · BLACKWELL
DGX Spark
spt-node1 · SM 12.1a
128 GB
MÉMOIRE UNIFIÉE · UMA
UNIFIED MEMORY · UMA
vLLMNeMoCUDA 13
x86_64 · ADA LOVELACE
2 × RTX 4090
spt-node2 · SM 8.9
48 GB
VRAM · 24 GB PAR GPU
VRAM · 24 GB PER GPU
vLLMdiffusersCUDA 13
aarch64-darwin · METAL 3
MacBook M3 Max
spt-node-mac · oMLX
64 GB
UMA · ~50 GB UTILISABLES
UMA · ~50 GB USABLE
oMLXKV cacheMLX-LM
DROP-IN OPENAI
DROP-IN OPENAI
Changez la base URL. Gardez votre code.
Change the base URL. Keep your code.
SDK OpenAI · même contrat
OpenAI SDK · same contract
N'importe quel client OpenAI (Python, Node, curl) marche sans modification. Authentification par Bearer, streaming SSE, passthrough des paramètres spécifiques au modèle (guidance_scale, num_inference_steps, …).
Any OpenAI client (Python, Node, curl) works without modification. Bearer auth, SSE streaming, passthrough for model-specific parameters (guidance_scale, num_inference_steps, …).
Authentification par clé API · rate limits configurables par clé
API key authentication · per-key configurable rate limits
Streaming SSE pour /chat et /completions
SSE streaming for /chat and /completions
Quotas journaliers · tokens · temps GPU · concurrence
Daily quotas · tokens · GPU time · concurrency
Bundle MCP pour Claude Desktop, Claude Code et tout hôte MCP
MCP bundle for Claude Desktop, Claude Code and any MCP host
fromopenaiimportOpenAIclient=OpenAI(
base_url="https://models.sponge-theory.dev/v1",
api_key="sk-...",
)
# Same SDK, every modality:chat=client.chat.completions.create(
model="gemma-4-26b-a4b-it",
messages=[{"role": "user", "content": "hi"}],
stream=True,
)
img=client.images.generate(
model="z-image-turbo",
prompt="a Blackwell GPU on a beach",
size="1024x1024",
)
emb=client.embeddings.create(
model="jina-embeddings-v5",
input=["hello", "world"],
)
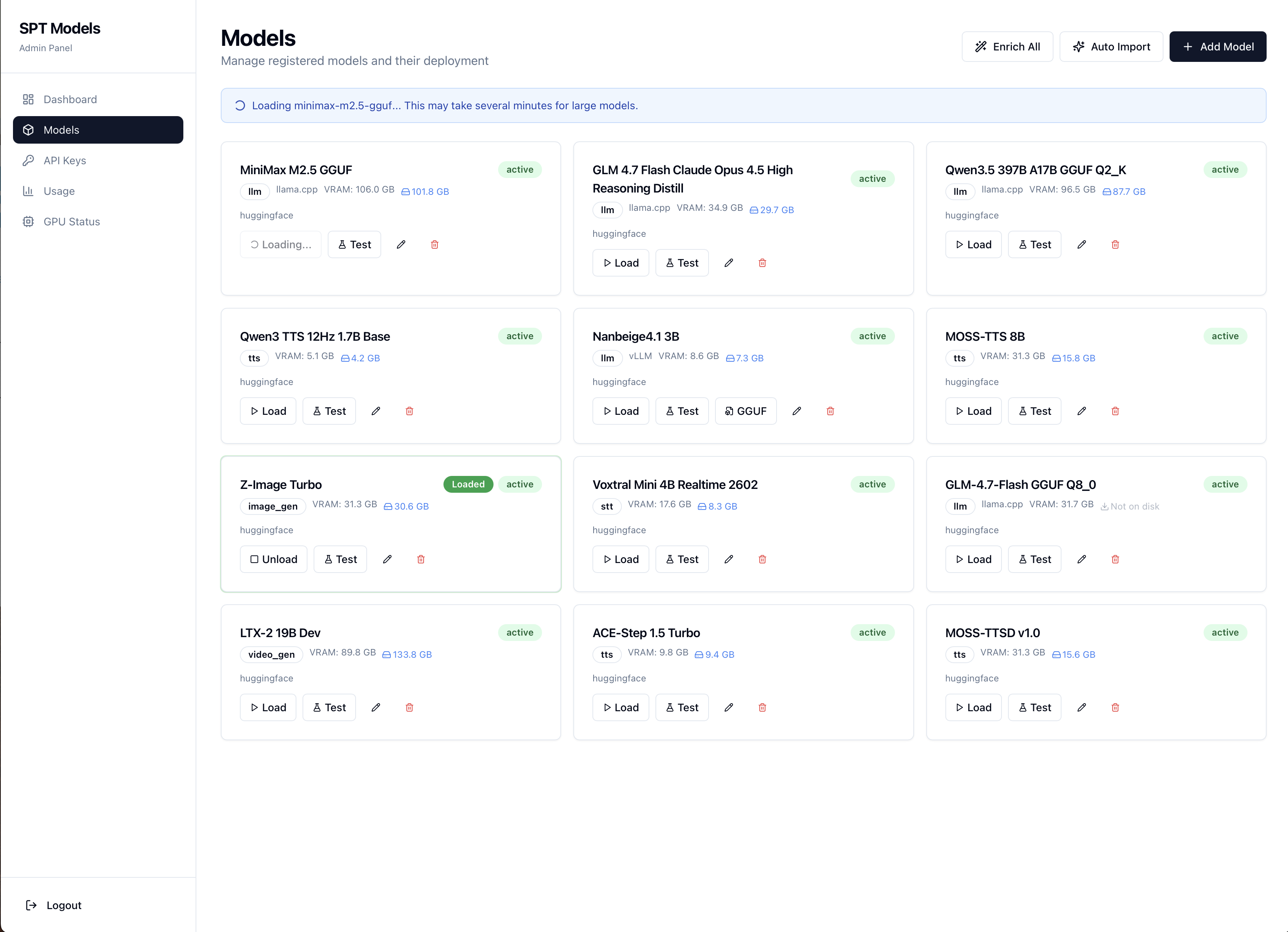
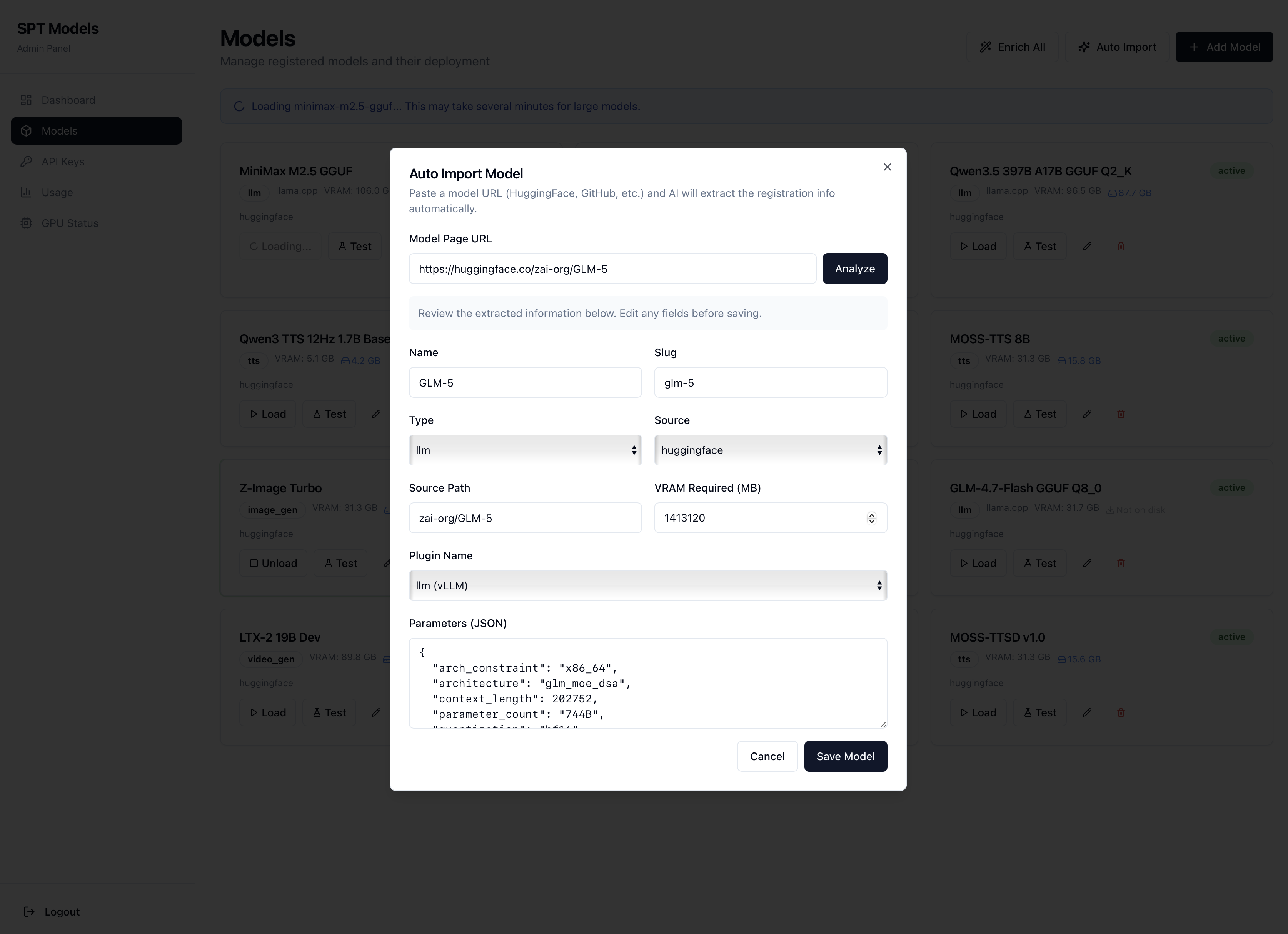
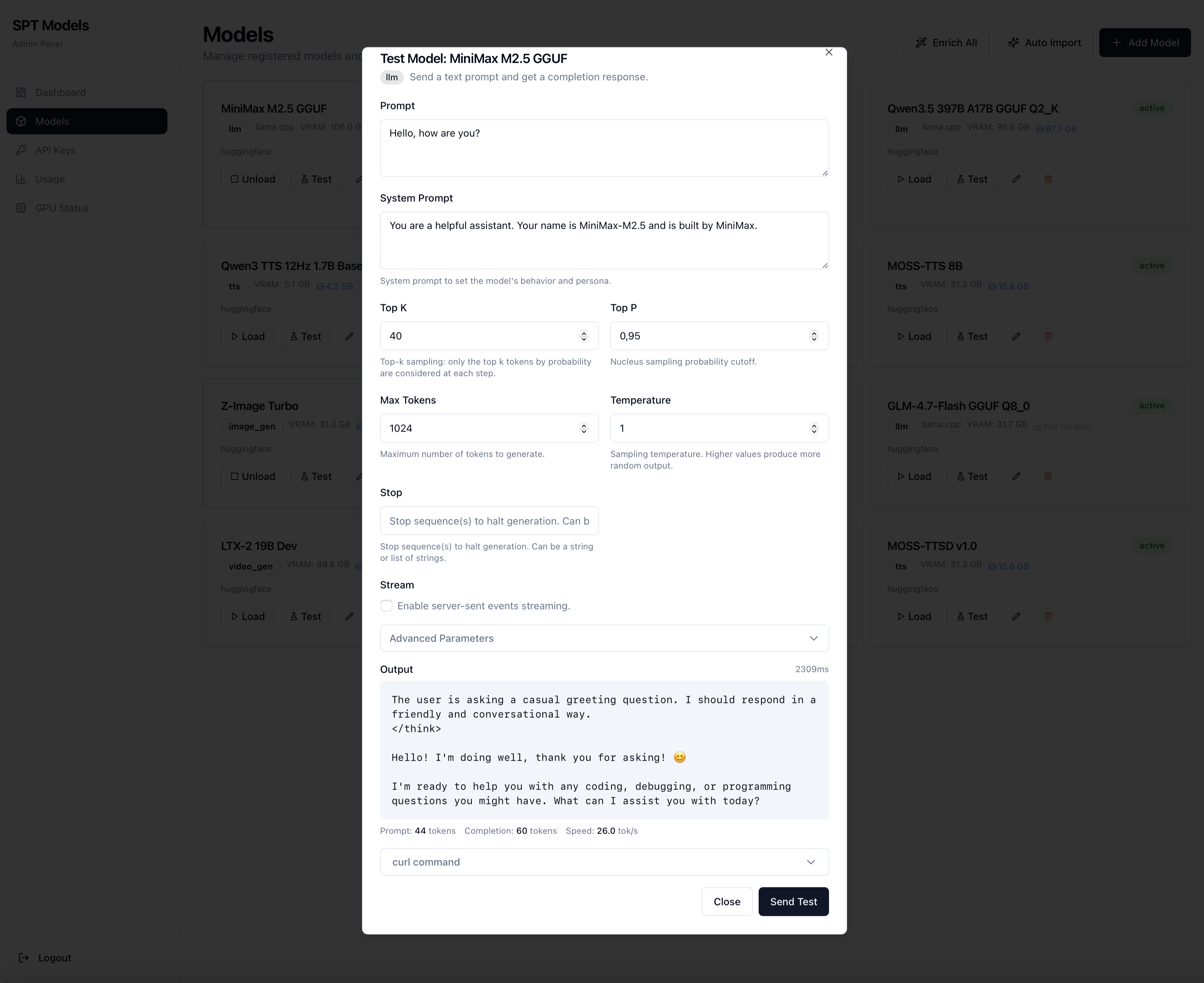
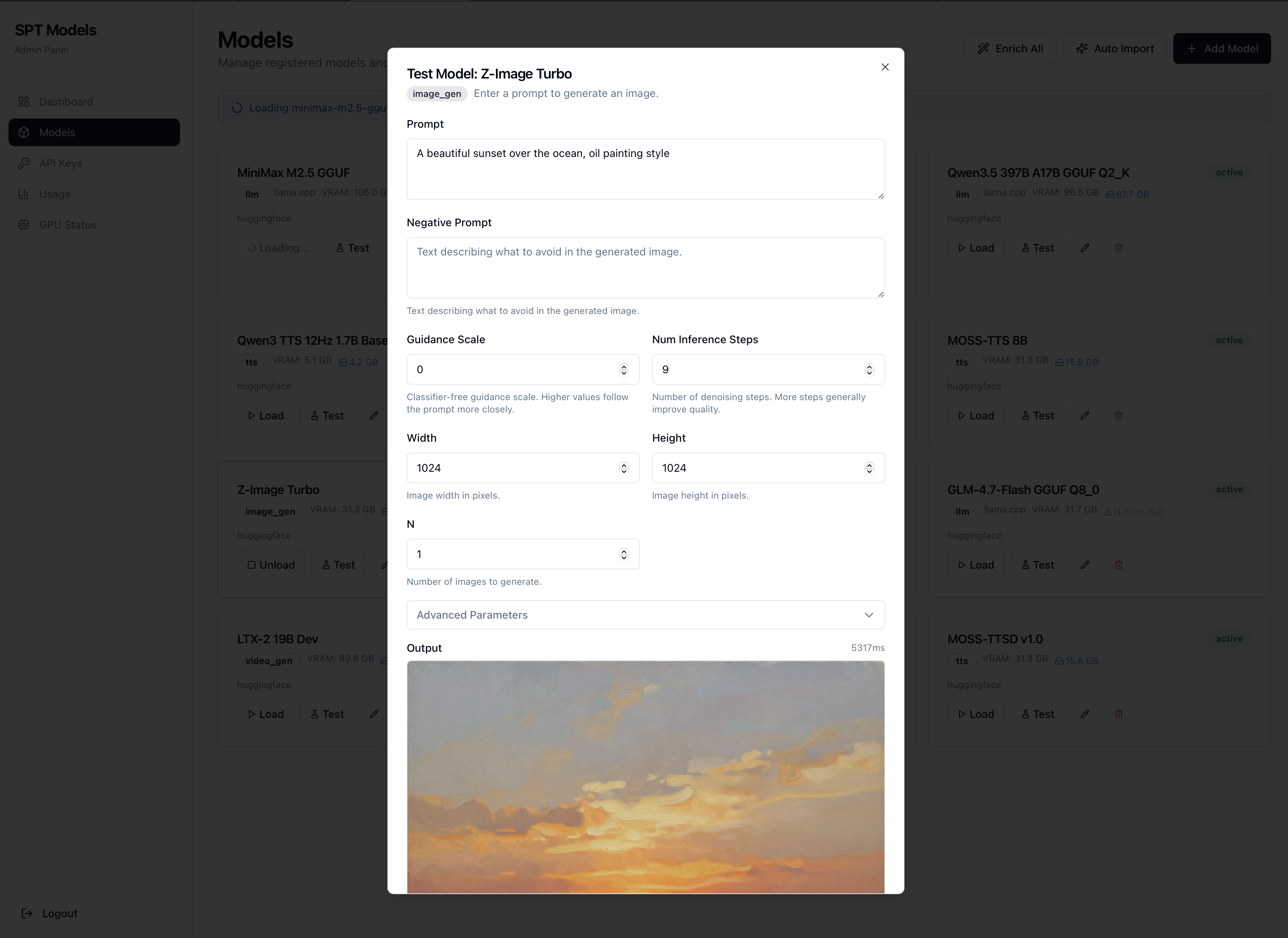
Catalogue par cartes, chargement live, formulaires de test générés à partir du schéma de paramètres du plugin. Import IA depuis une URL HuggingFace. Statistiques d'usage par modèle et par clé. Suivi de la conversion GGUF.
Card-based catalogue, live loading, test forms generated from the plugin's parameter schema. AI import from a HuggingFace URL. Usage stats by model and key. GGUF conversion tracking.
/admin/models · charger, décharger, tester, éditer en un clic./admin/models · load, unload, test, edit in one click.Auto-import IA · URL HuggingFace → metadata extraite.AI auto-import · HuggingFace URL → extracted metadata.Test live · formulaire dynamique par schéma de paramètres.Live test · dynamic form from parameter schema.Image gen · guidage, steps, taille, en direct depuis le panneau.Image gen · guidance, steps, size, live from the panel.
PRÉT POUR LA PRODUCTION
PRODUCTION-GRADE
Conçu pour les pannes, pas pour les démos.
Engineered for failure, not demos.
Chaque mécanisme d'isolation, de quarantaine et de fallback s'enclenche silencieusement. CUDA 13 natif sur Blackwell. Disjoncteurs MLX. Détection VRAM à quatre niveaux. Décodage spéculatif MTP. Venvs isolés par modèle.
Every isolation, quarantine and fallback mechanism trips silently in the background. CUDA 13 native on Blackwell. MLX circuit breakers. Four-level VRAM detection. MTP speculative decoding. Per-model venv isolation.
01
CUDA 13 · natif Blackwell
CUDA 13 · Blackwell native
Wheels cu130, FlashInfer, Tensor Cores TF32. TORCH_BLAS_PREFER_CUBLASLT et enforce_eager pour les contournements cuBLAS automatiquement.
cu130 wheels, FlashInfer, TF32 Tensor Cores. TORCH_BLAS_PREFER_CUBLASLT and enforce_eager for cuBLAS workarounds applied automatically.
02
Isolation venv par modèle
Per-model venv isolation
Volume venv persistant. Les dépendances d'un modèle ne peuvent jamais fuir vers un autre. Plus de conflits entre transformers v4 et v5.
Persistent venv volume. A model's dependencies cannot leak into another. No more transformers v4-vs-v5 conflicts.
03
Disjoncteur MLX
MLX circuit breaker
Un nœud oMLX qui ne répond plus est mis en quarantaine. Le scheduler reroute vers les nœuds CUDA. Reconnexion automatique au retour.
An unresponsive oMLX node is quarantined. The scheduler reroutes to CUDA nodes. Automatic reconnection on recovery.
04
Décodage spéculatif · MTP
Speculative decoding · MTP
Gemma 4 MTP drafter activé via parameters.speculative_config JSONB. Retry sécurisé sur les anciennes versions vLLM.
Gemma 4 MTP drafter enabled via parameters.speculative_config JSONB. Safe retry on older vLLM versions.
05
Détection VRAM 4 niveaux
4-level VRAM detection
NVML → torch.mem_get_info → device_properties → /proc/meminfo. Fonctionne sur les UMA (DGX Spark, Apple Silicon) où NVML retourne zéro.
NVML → torch.mem_get_info → device_properties → /proc/meminfo. Works on UMA systems (DGX Spark, Apple Silicon) where NVML returns zero.
06
Éviction LRU · cache KV
LRU eviction · KV cache
Quand un GPU sature, les modèles les moins utilisés sont déchargés automatiquement. Sur Apple Silicon, le cache KV tiered survit aux redémarrages.
When a GPU saturates, the least-recently-used models are evicted automatically. On Apple Silicon, the tiered KV cache survives restarts.
07
Auto-import IA · Claude
AI auto-import · Claude
Collez une URL HuggingFace : Claude lit le model card, le config.json, sélectionne le backend, estime la VRAM, choisit la quantization, écrit le loader si nécessaire.
Paste a HuggingFace URL: Claude reads the model card, config.json, selects the backend, sizes VRAM, picks the quantization, writes a loader if needed.
08
Sécurité · auth interne · SSRF
Security · internal auth · SSRF
Token interne service-à-service, allowlist d'hôtes, blocage IP privées sur auto-import, validation regex des slugs, sanitization de chemin sur tout cache cleanup.
Service-to-service internal token, hostname allowlist, private-IP blocking on auto-import, regex slug validation, path sanitization on every cache cleanup.
Une API. Toutes les modalités. Votre flotte.
One API. Every modality. Your fleet.
Discutons d'un déploiement sur votre matériel — DGX Spark, RTX, Apple Silicon, ou un mix.
Let's discuss a deployment on your hardware — DGX Spark, RTX, Apple Silicon, or a mix.